- A dataset - Data to evaluate the models on
- Models to evaluate - The models you want to assess
- Graders - Functions that will score the model outputs
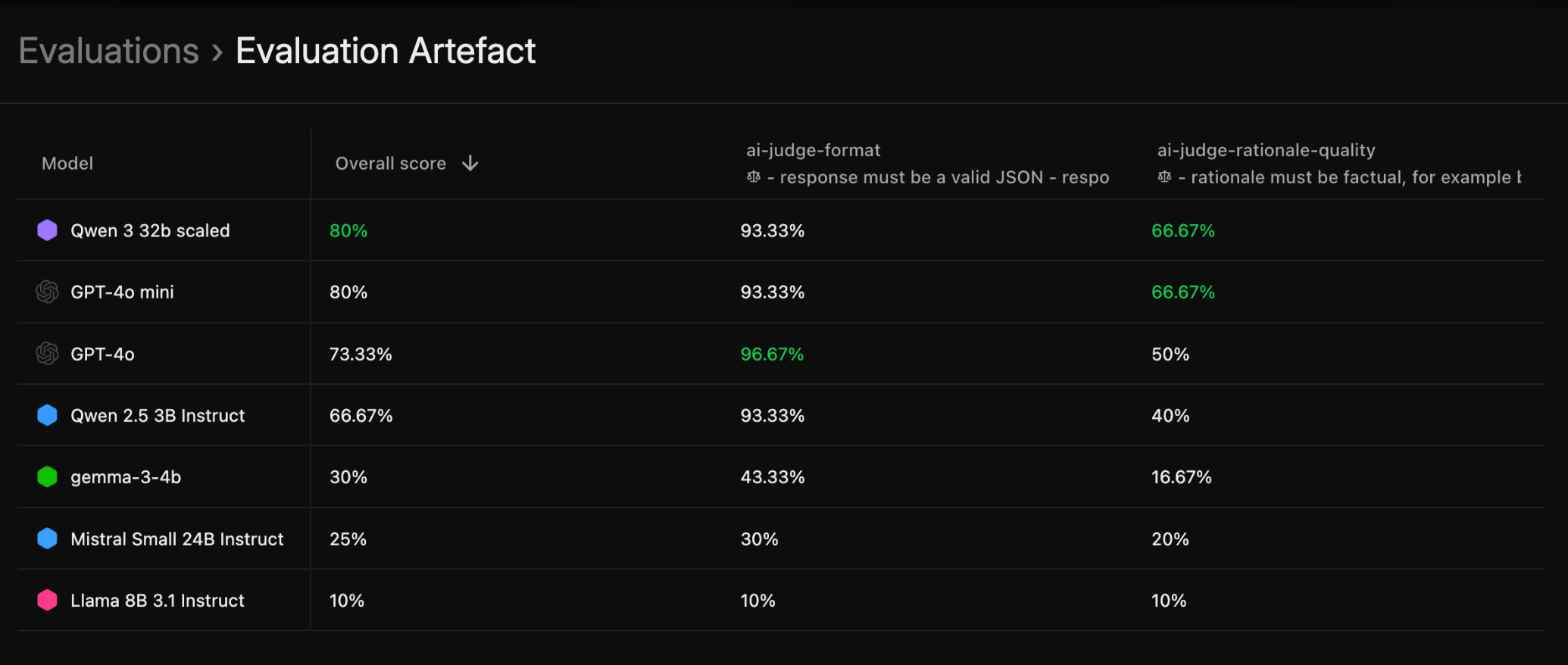
EvaluationArtifact, which will be populated with several EvalSample (evaluated model’s completions with attached grades). When you visit the Adaptive UI, and EvaluationArtifact will show aggregate evaluation scores per model on all Graders selected/created in the evaluation.
Evaluation Recipe Structure
In the previous sections, we omit wrapping all methods in the main function decorated with @recipe_main (see context here) for readability. Assume all the following code is in the main function. Also, check Parametrize recipe inputs to learn how to build the recipe
config with datasets, models and graders we refer to in the next steps.1. Load a Dataset
2. Spawn models and generate completions
To evaluate your models, you’ll generate a list ofEvalSampleInteraction by spawning each model, running inference to obtain completions, and collecting the results.
Use the spawn_inference method to create an inference instance for each model. After generating completions, deallocate the model to optimize memory usage.
async_map_fallible is an util function that concurrently processes all samples and skips completions with errors (when for example the sample is too big for the model’s maximum sequence length).
3. Spawn graders and grade completions
To evaluate model outputs, we need to create/setup graders, and use them to grade each model’s completions. Each Grader produces a Grade for each sample.If you defined a custom Recipe Grader in this eval recipe, you could add it to the
graders list above, have its grades added to eval_samples and later shown in the UI. If the grader_key you hardcode for you recipe grader does not exist yet in the platform, it will be automatically created and reported in the evaluation results; no need to pre-create the recipe grader.4. Output an EvaluationArtifact
Now that all samples are graded, you can create anEvaluationArtifact and populate it with your EvalSamples.
You do not need to push this to Adaptive with a specific method; the Adaptive Engine automatically detects that an EvaluationArtifact was written in the course of the recipe’s execution, registering and displaying it in the UI once the run is complete.
Complete Evaluation Recipe Example
Here’s a complete example combining all the concepts:Key Components Explained
Evaluation Samples
Each evaluation sample contains:- Interaction: The model’s response and source model key
- Grades: Grades from all graders
- Dataset ID: Reference to the source dataset
Graders
Graders can be:- AI Judge Graders: Use LLMs to score responses
- Rule-based Graders: Apply predefined criteria
- Combined Graders: Aggregate multiple grader scores
Evaluation Artifact
TheEvaluationArtifact class:
- Collects all evaluation results
- Provides methods to analyze and export results
- Integrates with the Adaptive platform for result tracking
Best Practices
- Model Management: Always deallocate models after use to free resources
- Error Handling: Use proper error handling for robust evaluation
- Progress Tracking: Provide clear logging for debugging and monitoring
- Resource Cleanup: Properly clean up graders and models