Overview
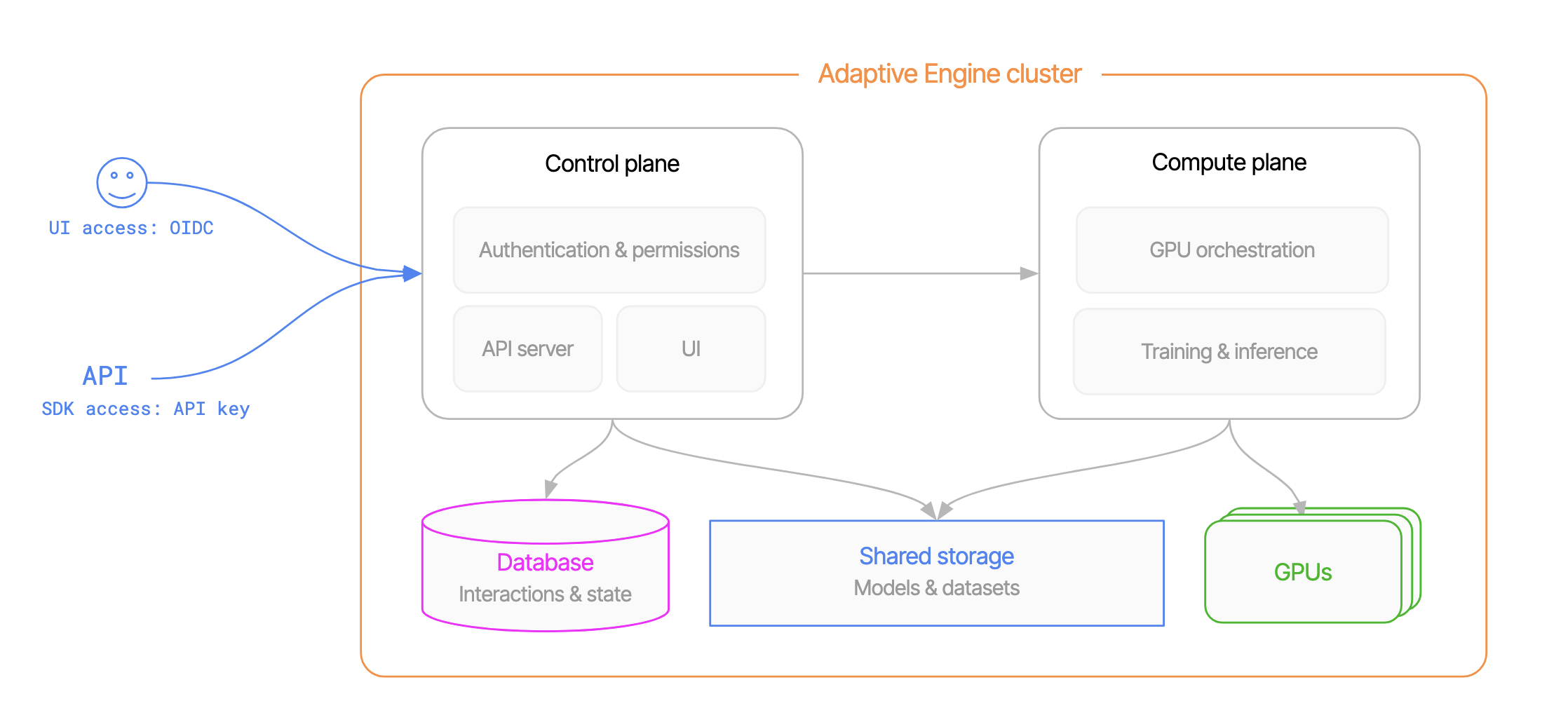
An Adaptive Engine cluster consists of 4 architectural components:- Control plane: hosts the UI, permissions system and user-facing APIs.
- Compute plane: spans one or multiple GPU servers, runs AI inference and training.
- Shared storage: stores model files and training artifacts.
- Database: stores model interactions, projects metadata and overall application state.
Components
Control plane
The control plane is a low-latency, containerized service, which serves the platform’s user interface and APIs. It runs on CPU and needs as little as 4vCPU and 16GB memory.Compute plane
The compute plane is a high-performance, multi-modal, multi-GPU, multi-node AI computing framework capable of large scale model training and inference. It is purpose-built for the most demanding modern AI workloads, including reinforcement learning (RL), pre-training, and high-concurrency multi-model inference- The compute plane is compatible with the following NVIDIA GPUs: L40, L40S, A100, H100, H200, B200, GB200.
- The compute plane can run both on multi-GPU servers or single-GPU servers.
- The presence of intra-node GPU interconnect (NVLink) is optional, though recommended for training and large-model inference.
- The compute plane is compatible with PCIe-connected multi-GPU servers, such as Amazon EC2 g6.12xlarge or g6e.12xlarge.
Shared storage
The shared storage stores model files and datasets. It can be any POSIX-compatible storage (local disk, NFS) or S3-compatible object storage.Database
The database is a v16+ Postgres database which stores model interactions and application metadata, including user permissions and settings. To enforce maximum security, blocking permissions checks are run at each inference, meaning the database must be located sufficiently close to the control plane to avoid penalizing inference performance.Examples
The below table gives examples of cloud services that can power each component:Architecture observations
- Adaptive Engine is built on open standards (Linux, Postgres, Rust, Docker) ensuring low infrastructure lock-in and high portability. Adaptive Engine clusters have been successfully deployed across hyperscalers (AWS, Google Cloud, Microsoft Azure), several neoclouds and on-premises data centers across Asia, Europe and North America.
- The four Adaptive Engine components can be all collocated, so that an Adaptive Engine cluster can technically fit within a single self-sufficient server with no reliance on any extra cloud services.
- In practice, for sustained use we recommend the use of an external database and an external storage to facilitate the independent scaling of each component, increase availability and limit the blast radius of failures.
- We recommend GPU VMs to have 300GB+ of local storage to accommodate Docker images and model local cache.
Compute plane deep dive
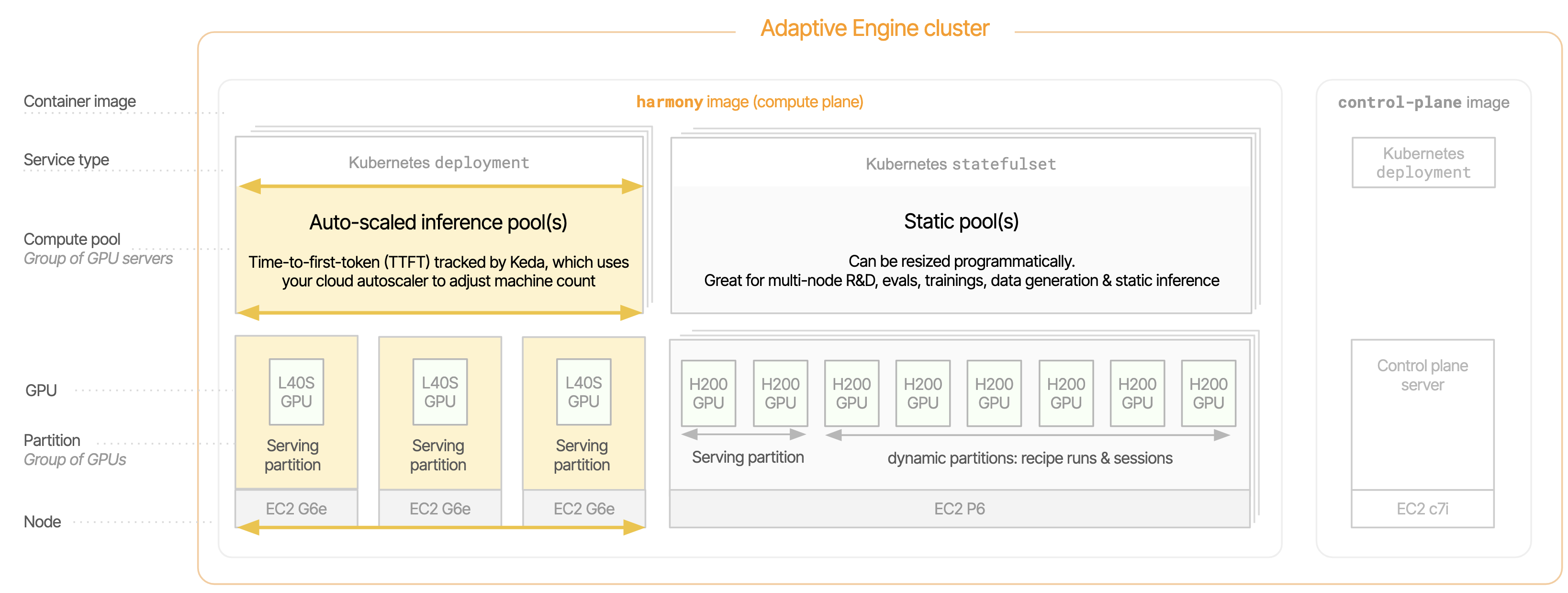
Compute pools
A compute pool is a cell of one or multiple homogeneous servers that receives one or multiple GPU workloads. There are two types of compute pools:- Inference pools support inference endpoints only, and can optionally be autoscaled. Read more in the Adaptive Engine Helm Chart.
- Static pools support an arbitrary amount of stateful servers and cannot be autoscaled. They can however be scaled up and down programmatically with minor transition time.
GPU workloads
Adaptive Engine runs 3 types of GPU workloads:- Inference endpoints, which serve models for low-latency, high-throughput real-time inference and offer a variety of features and controls. Read more in the inference optimization page.
- Recipe runs, which are scripted, used-defined batch tasks. Model training, fine-tuning, data generation and evaluation can be scripted as recipe runs. Read more about runs in the runs page.
- Interactive sessions, which allow you to directly connect to a GPU via Secure WebSockets for real-time, remote execution of client-side code. Read more about sessions in the recipe page.
- Inference endpoints can run on a combination of multiple inference or static compute pools, making your model deployments scalable and fault-tolerant.
- Recipe runs and interactive sessions run only on static pools.
- Within a static pool, it is possible to control the amount of GPUs allocated to recipe runs and interactive sessions using the environment variable
ADAPTIVE_EXCLUSIVE_PARTITION_SIZE. For example, on a static pool of 8 x H200 servers cumulating a total of 64 H200 GPUs,ADAPTIVE_EXCLUSIVE_PARTITION_SIZE=60means that 4 GPUs will be reserved for inference endpoint deployment, and 60 for recipe runs and interactive sessions.