- SDK
- UI
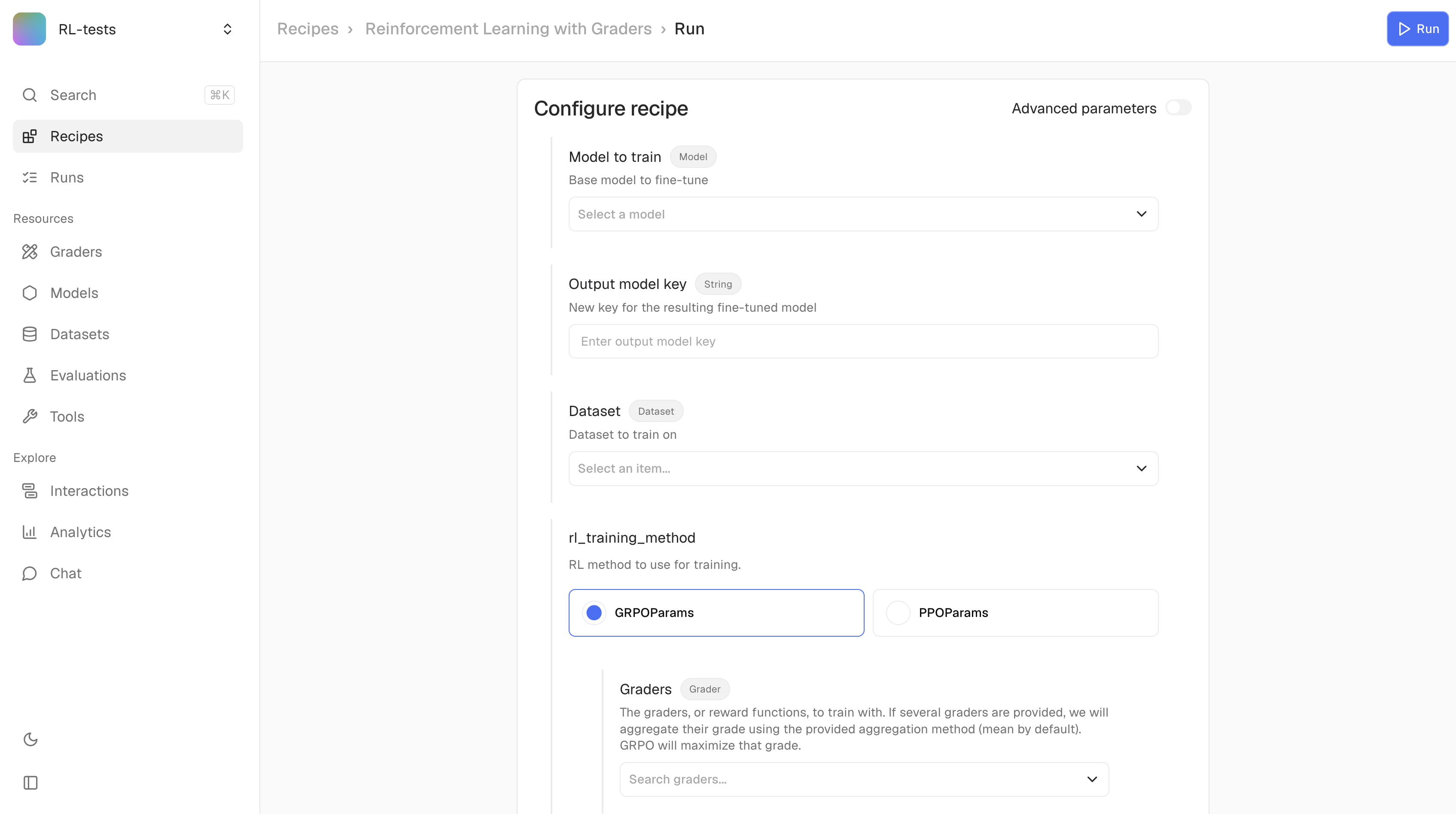
Run a recipe
| Parameter | Type | Required | Description |
|---|---|---|---|
recipe_key | str | Yes | Recipe identifier (see below) |
num_gpus | int | Yes | Number of GPUs to use |
args | dict | No | Recipe-specific arguments (defaults to empty) |
Common training arguments
| Argument | Type | Default | Description |
|---|---|---|---|
data_seed | int | 42 | Seed for dataset shuffling. Set for reproducible training runs. |
checkpoint_frequency | float | 0.2 | Fraction of total training steps between saves. 0.2 = save every 20% of training (5 checkpoints per run). |
sft, preference_rlhf, metric_rlhf, rl) support both arguments. Evaluation recipes use neither.Built-in recipes
Training:| Recipe | Key | Use when |
|---|---|---|
| Supervised fine-tuning | sft | You have high-quality completions |
| RL on preferences | preference_rlhf | You have preferred/rejected pairs |
| RL on metrics | metric_rlhf | You have completion-level scores |
| RL with grader | rl | Criteria can be expressed in natural language |
| Recipe | Key | Use when |
|---|---|---|
| Evaluate with grader | eval | Comparing model performance |
| Recipe | Key | Use when |
|---|---|---|
| Speculative decoding alignment | specdec_alignment | You want to accelerate inference with a draft model |
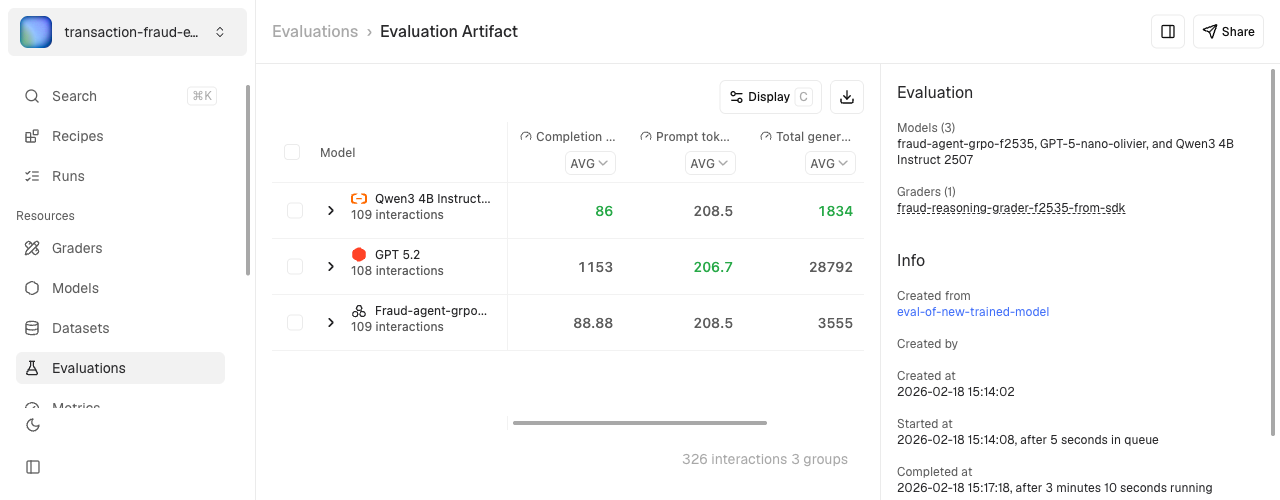
Run an evaluation
Resume an interrupted run
Resume picks up from the last saved checkpoint and keeps the same job ID — it does not fork a new run. Resume from the Runs tab in the UI, or re-launch the job with resume enabled.Resume is step-level, not epoch-level. Multi-stage runs (currentlypreference_rlhf, which orchestrates DPO / PPO / GRPO under one recipe) track each stage’s progress independently — resume picks up at the active stage’s last checkpoint, not the first stage.