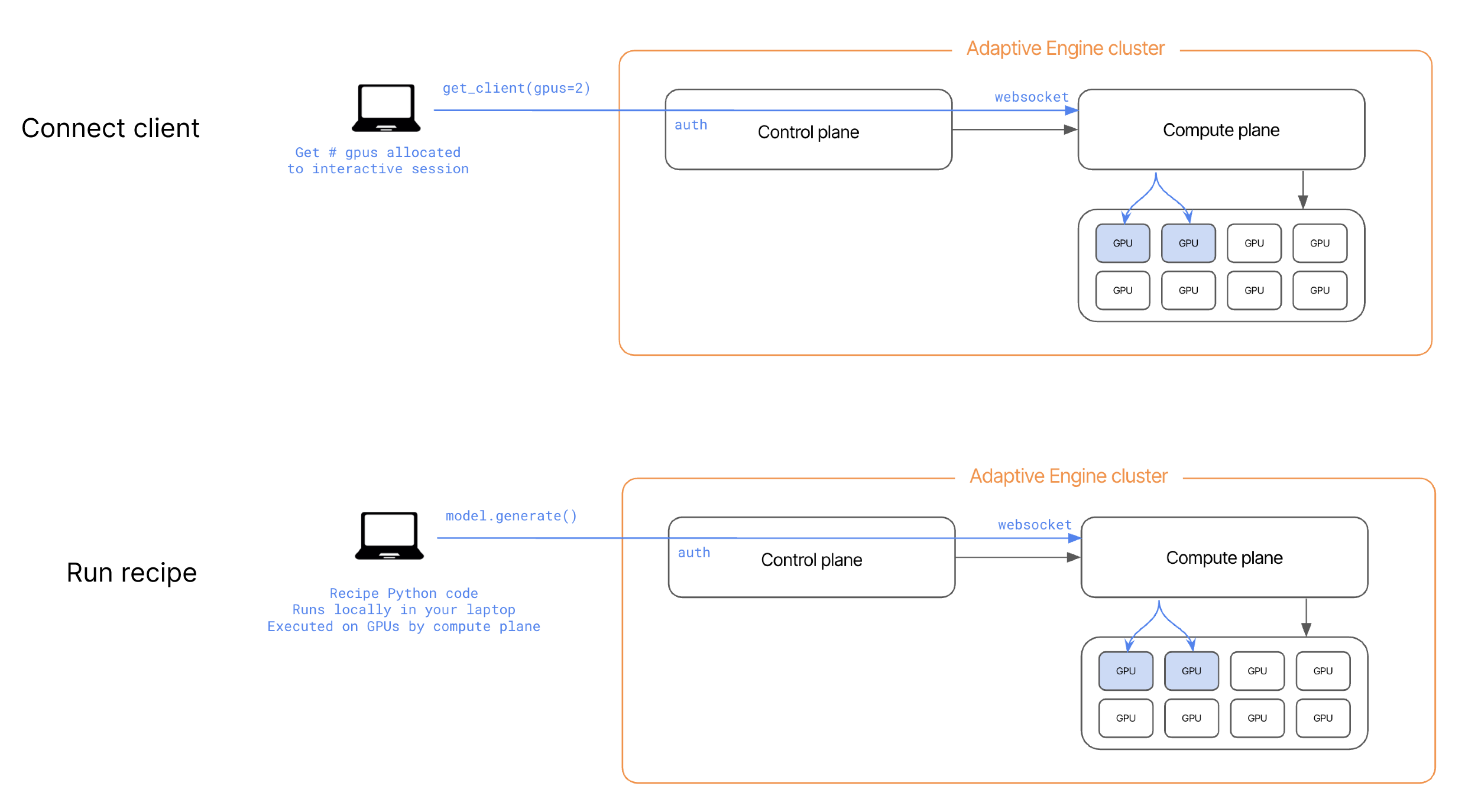
adaptive_harmony allows you to establish a direct connection via secure websockets between your local environment and the compute plane of your Adaptive Engines’ deployment. When you instantiate a HarmonyClient, a desired number of GPU’s is allocated directly to you as an interactive session. These GPU’s are freed to run other workloads or interactive sessions as soon as the local python process holding that client in memory is killed.
If you use
adaptive_harmony in a Jupyter Notebook, you can directly await async methods like get_client in a Jupyter cell (i.e. await get_client()), no need to use asyncio.spawn method to spawn a model on GPU, you’ll get back a new handle in Python to a remote model, such as TrainingModel or InferenceModel, which you can also call methods on (such as .generate(), .train_grpo(), .optim_step(), etc.). This create a hybrid development environment, where you can step through python recipe code locally in your IDE, but have powerful compute resources execute the methods that require them.
RecipeContext (ctx).