- Control plane - UI, permissions system, user-facing APIs
- Compute plane - GPU servers for inference and training
- Shared storage - Model files and training artifacts
- Postgres database - Interactions, metadata, application state
- Redis - Job events and usage statistics
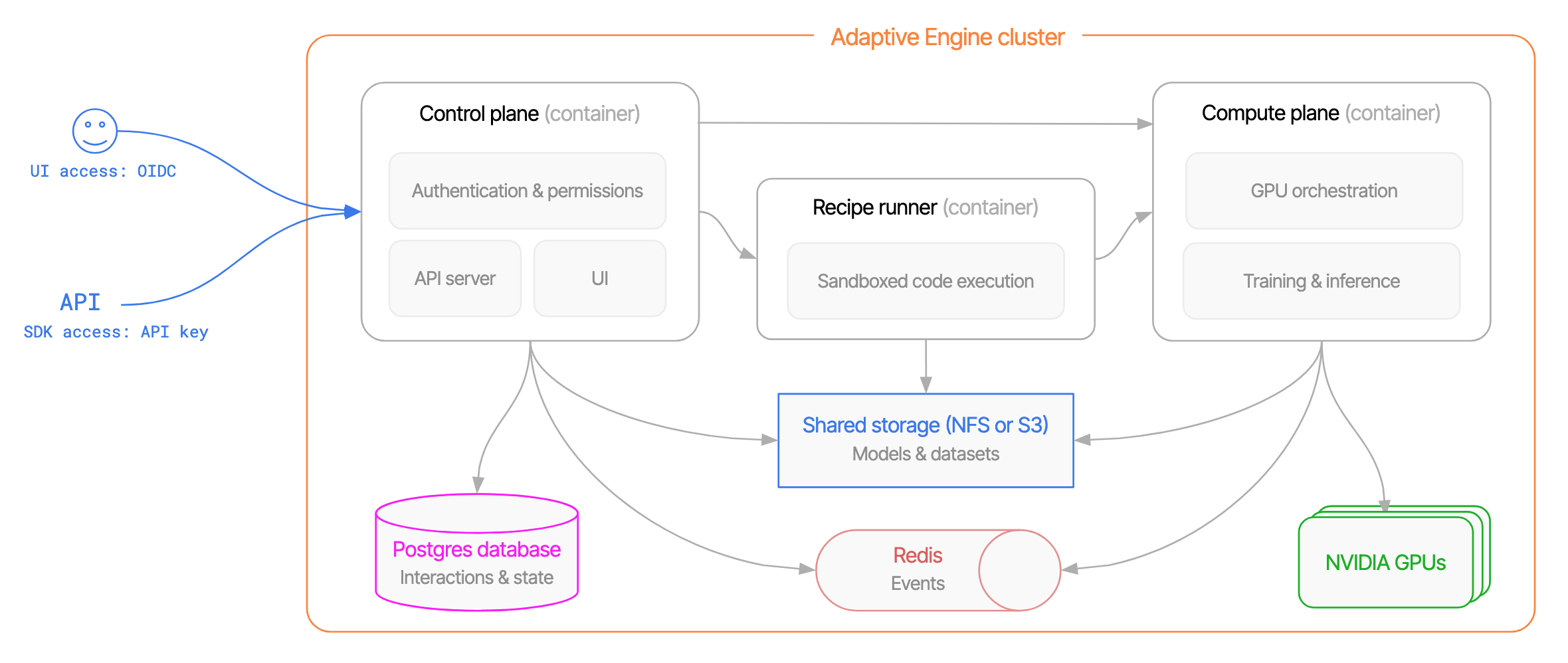
High-level overview of Adaptive Engine system architecture
Components
Control Plane
Low-latency containerized service serving the UI and APIs. Runs on CPU (minimum 4 vCPU, 16GB memory).Compute Plane
Multi-GPU AI computing framework for training and inference. Compatible GPUs: L4, L40, L40S, H100, H200, B200, GB200 Requirements:- Multi-GPU or single-GPU servers supported
- NVLink/NVSwitch optional but recommended for training and large models
- PCIe-connected multi-GPU servers supported (e.g., EC2 g6.12xlarge)
- 300GB+ local storage recommended for Docker images and model cache
Shared Storage
Model files and datasets. Any POSIX-compatible storage (local disk, NFS) or S3-compatible object storage.Database
PostgreSQL 16+. Stores interactions, permissions, and settings. Must be located near the control plane since blocking permission checks run on every inference call.Redis
Transfers events between compute and control planes, stores usage statistics and real-time metadata. Can be local or managed (Elasticache, Memorystore, etc.).Cloud Service Examples
Compute Plane
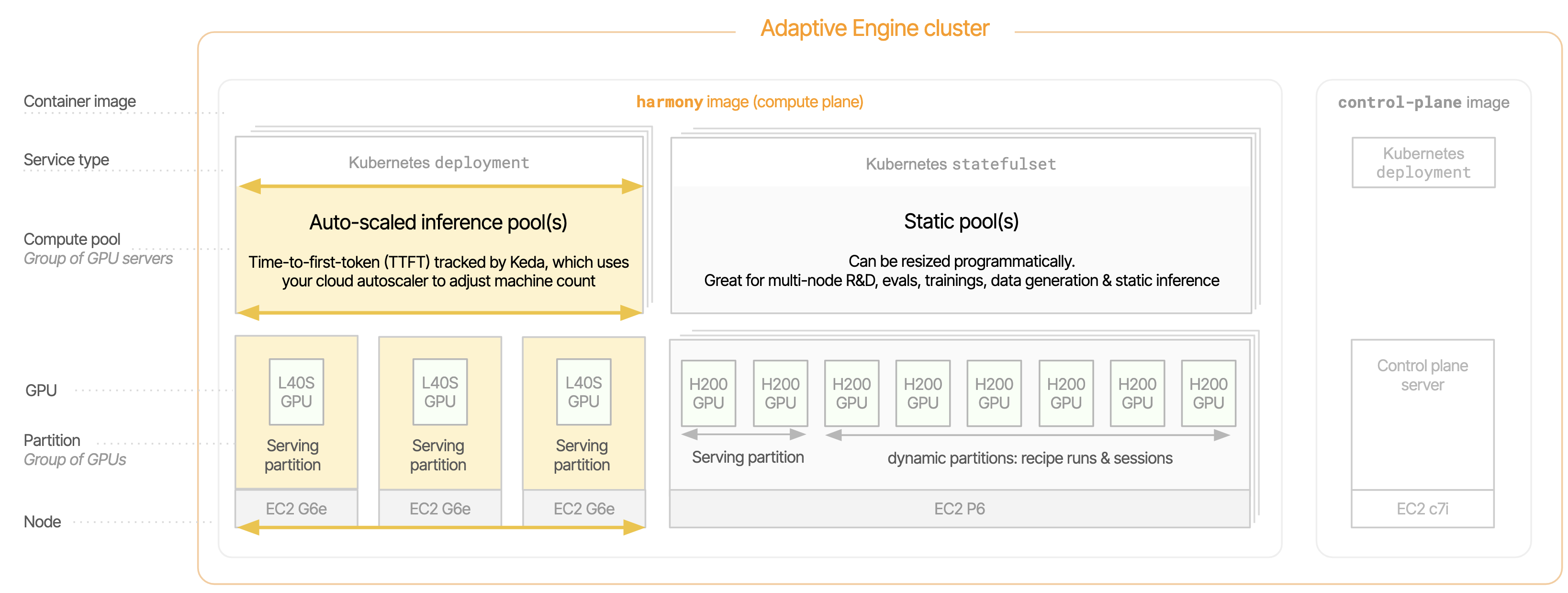
Detailed architecture of an Amazon EKS deployment with compute pools for training and inference
Compute Pools
A compute pool is a set of homogeneous GPU servers that receives workloads. A cluster can have multiple compute pools representing different GPU types or capacity reservations.GPU Workloads
- Inference endpoints - Low-latency, high-throughput model serving
- Recipe runs - Scripted batch tasks (training, fine-tuning, evaluation)
- Interactive sessions - Real-time remote execution via Secure WebSockets
- Inference endpoints can span multiple inference or static pools
- Recipe runs and sessions can only be on one compute pool
Deployment Notes
- Built on open standards (Linux, Postgres, Rust, Docker) for portability
- All 5 components can be collocated on a single server
- For production, we recommend to use an external database and storage for independent scaling and availability