Using adapters
By default, Adaptive Engine trains and serves adapters, even though users can decide to run full-parameter trainings as well. Adapters share the same backbone, so they increase the batching opportunity and reduce the quantity of weights kept up in memory in the cluster under load. The default number of adapters deployed in parallel is 4. Contact Adaptive ML support to increase that limit.
Intelligent stateful KV-cache
What is it?
Using a KV-cache allows to reuse some of the computations used to decode token N, namely the key-value output of self-attention layers, for the decoding of token N+1. The stateful KV-cache extends that concept to reusing computations from previously seen prompts, such as previous chat turns, in the decoding phase associated to a subsequent user turn in the same session. Increasing the KV-cache increases the likelihood of computation reuse, and also increases the number of sequences that can be batched together. Adaptive Engine is equipped with an intelligent stateful KV-cache, that decides, based on GPU occupancy and incoming traffic shape, whether to keep incoming session prompts pinned to a session-assigned model replica, or to rebalance the prompts to a fresh replica, that may return results faster even though if it comes at the cost of extra computation.Setting and tuning the Adaptive Engine stateful KV-cache
Adaptive Engine stateful KV-cache can be set in the model registry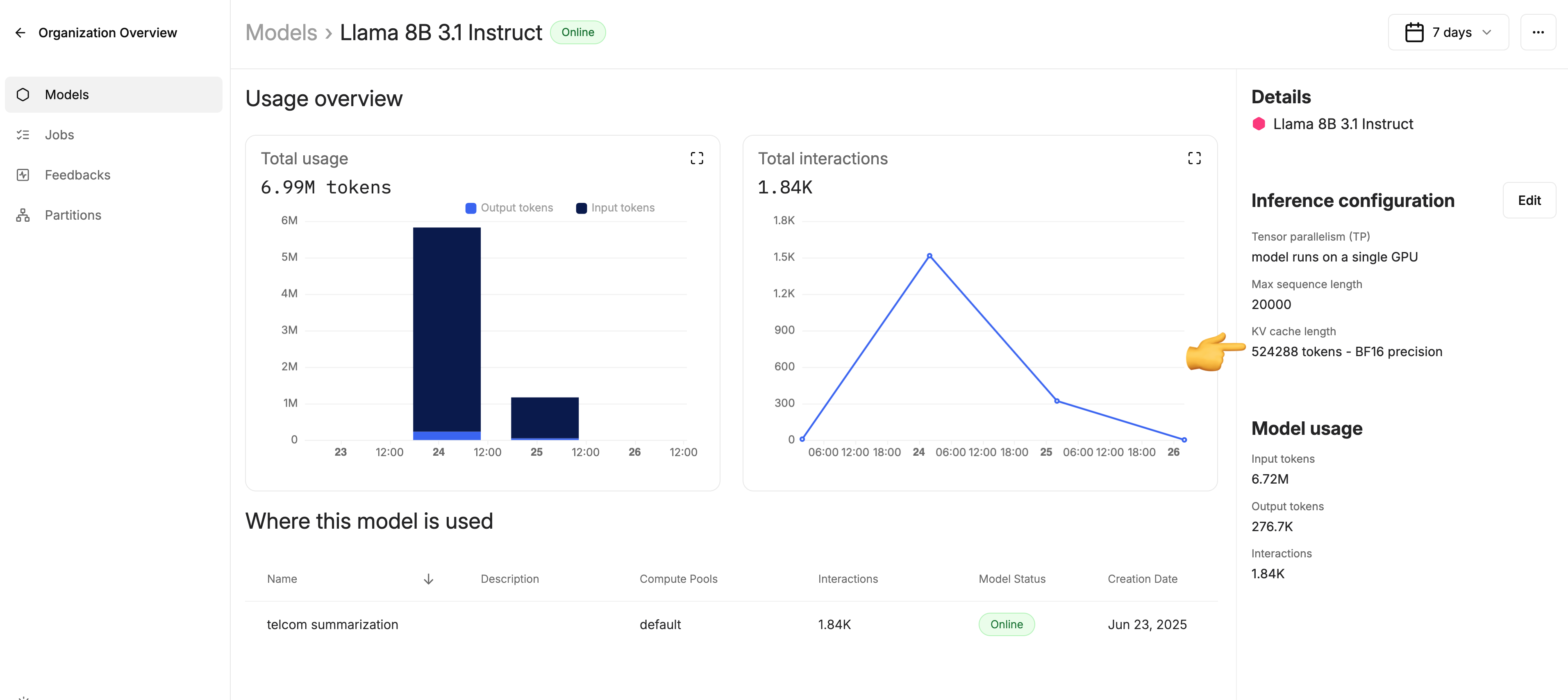
Adaptive SDK
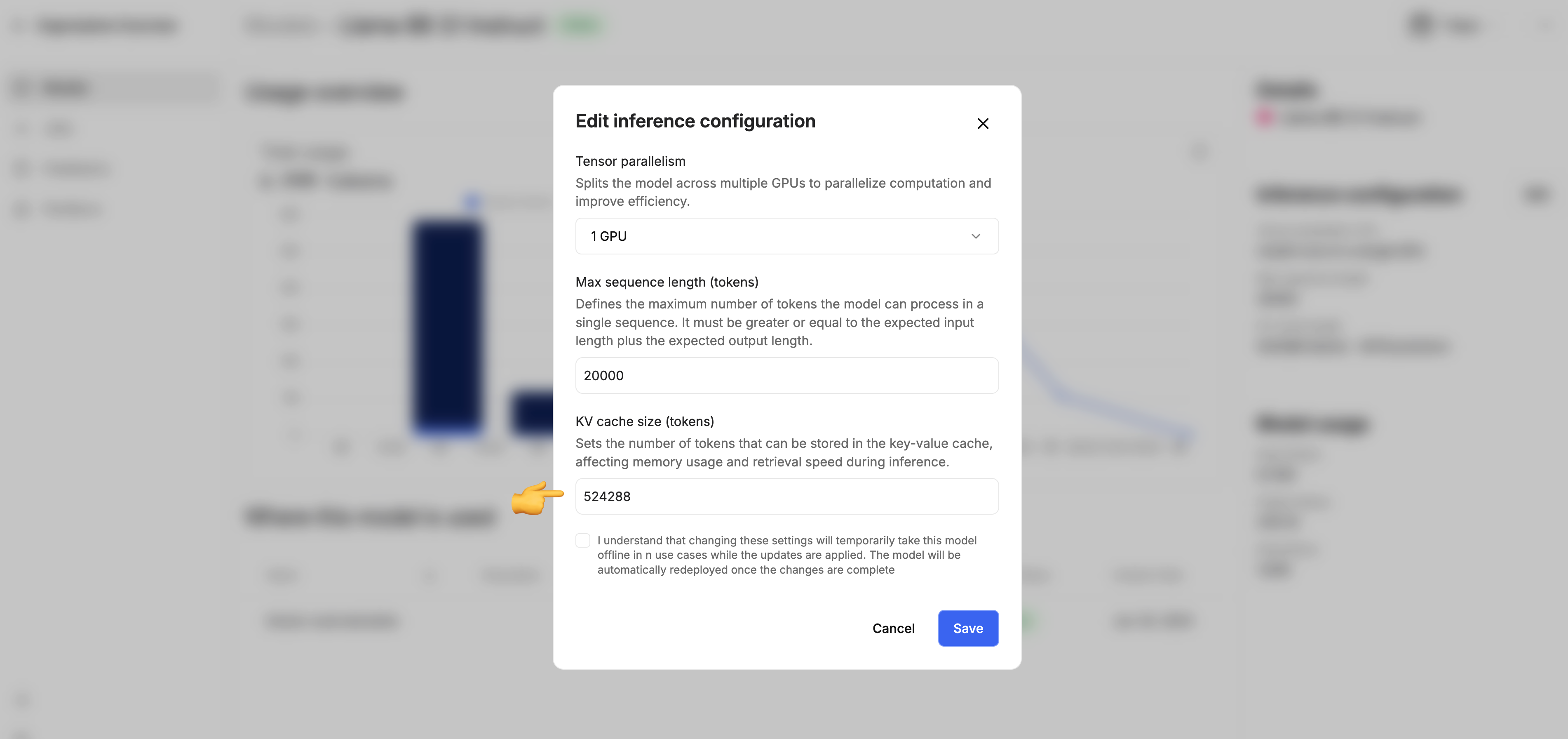
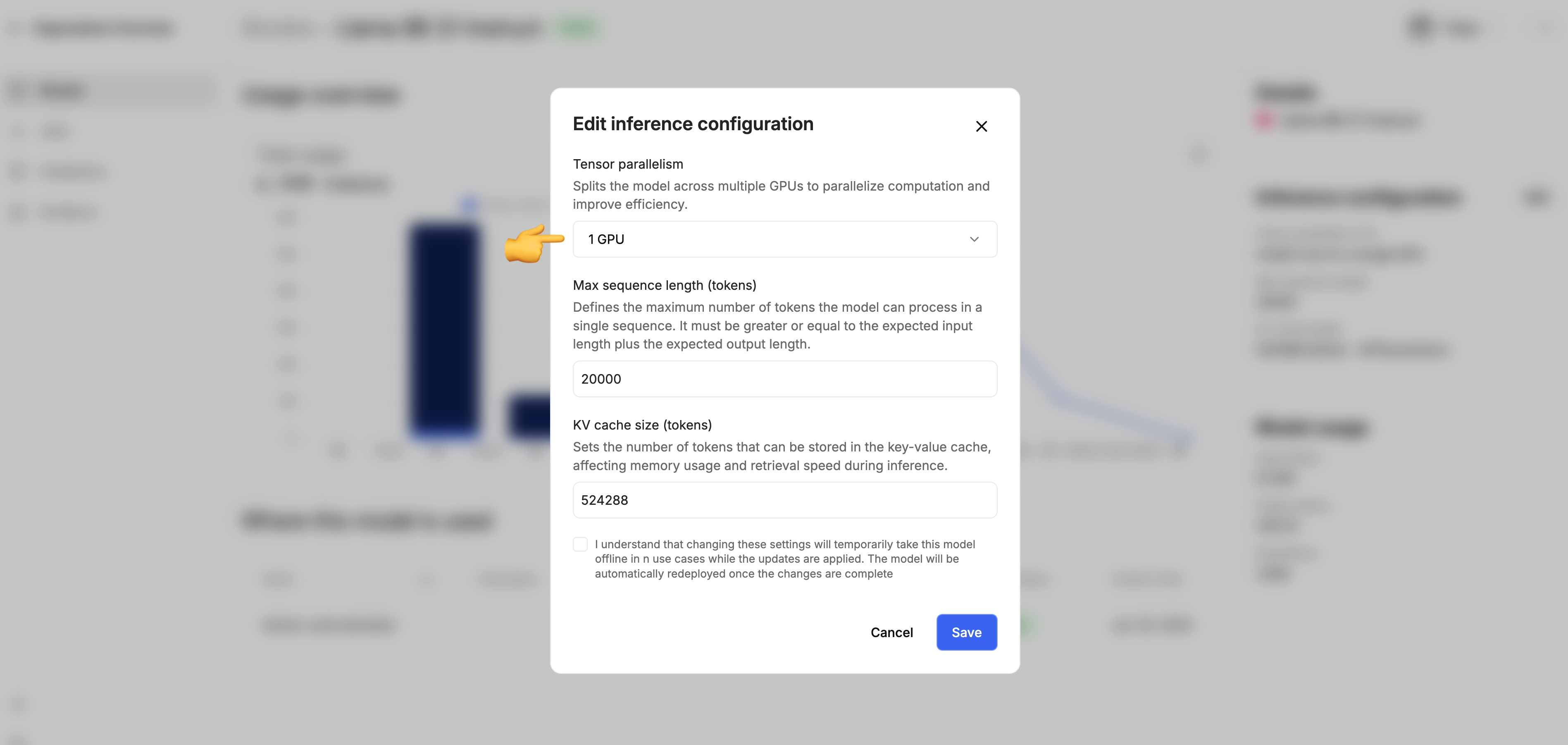
Tensor parallelism
Adaptive Engine allows you to customize the tensor parallelism (TP) of your models. TP represents the number of GPUs over which a model replica is partitioned.Changing the tensor parallelism
You can change the tensor parallelism in the Adaptive Engine model registry UI:
Adaptive SDK
Optimizing tensor parallelism
It is recommended to try different TP configuration, while being aware of the following considerations:- Increasing TP reduces the per-GPU memory footprint, hence allows use more KV-cache and thus more batching and computation reuse.
- Increasing TP generally leads to lower latency.
Automated replication
Adaptive Engine automatically creates more inference replicas as needed and if possible, based on your TP configuration, available GPUs and incoming traffic.You do not need to set or tune batching and data parallelism, Adaptive Engine does it automatically for you.
Timeouts
Adaptive Engine exposes 3 timeout controls. If you experience 408 or timeout errors we recommend to adjust them:ADAPTIVE_SERVER__TIMEOUT_SECONDS(default 60s): timeout for the HTTP requests handled inside the control plane. Set this timeout as a control plane environment variable.ADAPTIVE_HTTP_CLIENT__TIMEOUT_SECS(default 60s): timeout for the HTTP requests made from control plane to its dependencies such as Harmony and external models. Set this timeout as a control plane environment variable.max_ttft(default 60s): how long can a request wait before generating its first token.- If this is exceeded, the request will be dropped and a 408 error returned.
- It includes queueing time.
- It is used as a trigger metric when inference autoscaling is activated.
- It can be set via SDK, using:
Adaptive SDK
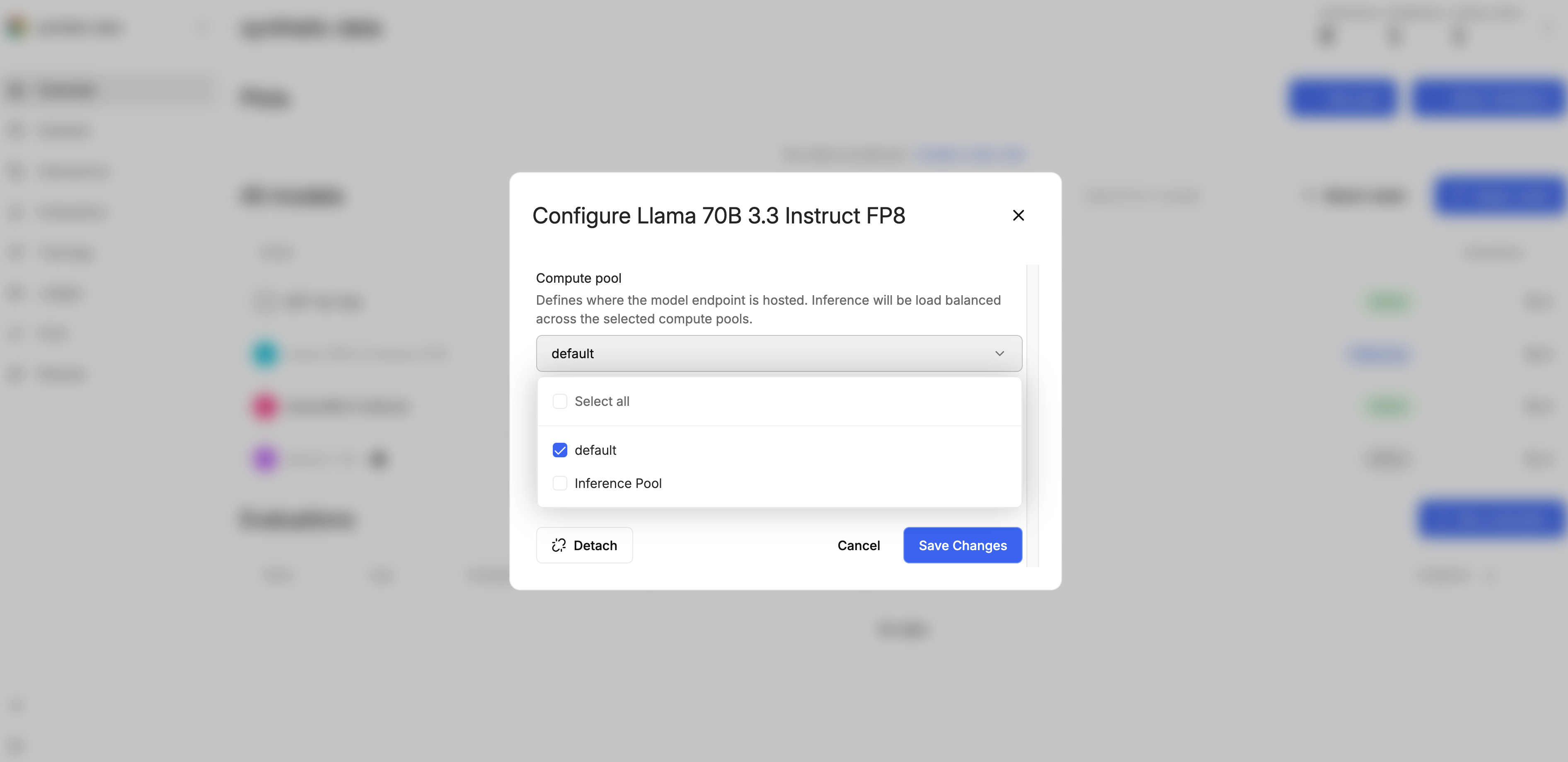
Compute pools and autoscaling
Adaptive Engine allows the creation of compute pools, which are isolated partitions of your cluster or node that can be assigned training, evaluation and inference tasks. You can adjust the number of compute pools hosting a model endpoint to increase its reliability and hardware footprint. Compute pools can be adjusted via UI and SDK: In the UI it is done in the use case Overview section:
Adaptive SDK
More tips
Models
To further reduce compute footprint and latency, consider using:- fp8 quantization support in Adaptive Engine.
- Smaller-size LLMs, that we often see outperform frontier models after their reinforcement fine-tuning on Adaptive Engine.
Database
Adaptive Engine implements a rigorous permission check that verifies permissions server-side for every inference call. To minimize database overhead, make sure to use a properly-sized database, located sufficiently close to your inference machines.Summary table
Overview of inference optimization avenues and their impact.