> ## Documentation Index
> Fetch the complete documentation index at: https://docs.adaptive-ml.com/llms.txt
> Use this file to discover all available pages before exploring further.
# AI Judge
> Evaluate models using AI feedback
Adaptive Engine allows you to evaluate models on logged interactions or datasets using AI feedback.
An AI Judge typically refers to using a powerful LLM to evaluate the performance of another LLM. Using LLMs as judges enables
cheap and effective model evaluation at scale, with little to no dependency on human automation and labor cost.
Adaptive includes both [pre-built](#pre-built-recipes) AI Judge evaluation recipes for common use cases (such as RAG),
and [custom](#custom-recipes) evaluation recipes where you can define your own evaluation criteria,
without having to deal with the complexities of an evaluation pipeline. It's up to you to decide what model you want to use as a Judge,
which includes connected [proprietary models](/v0.5/integrations/proprietary-models).
Evaluation jobs output an **average scalar score**, and a **textual judgement** corresponding to the
AI Judge's reasoning behind that score. You can view the evaluation score for each evaluated model in your use case page, and drill down on the judgements for individual
completions in the interaction store.
Adaptive Engine currently supports the following recipes:
## Pre-built evaluation recipes
#### **Faithfulness**
Measures a completion's adherence to the context or documents provided in the prompt.
This metric is useful for grounded generation scenarios such as Retrieval-Augmented Generation (RAG).
As a first step, the AI Judge breaks down the completion into individual atomic "claims".
The output score is an average, computed by the ratio of claims that are fully supported by the context / total number of claims made in the completion.
The textual judgement attached to each completion indicates what parts of the completion specifically deviate from the provided context.
The supporting documents must be passed in `document` turns in the input messages. You can add all retrieved context in a single turn,
but preferably each retrieved chunk should be added as a separate turn.
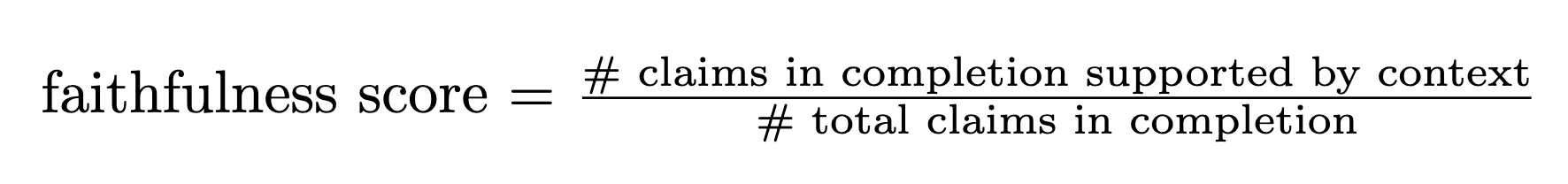 **Input messages**
```json theme={null}
[
{"role":"system", "content":"You are a helpful bot, that responds only based on the context provided."},
{"role":"document", "content": "The first website was created and published by Tim Berners-Lee."},
{"role": "document", "content": "Tim Berners-Lee is a computer scientist that invented the world wide web."},
{"role": "user", "content": "Who published the first working website on the world wide web?"}
]
```
**Completion**
```
The first website was published by Tim Berners-Lee in August 1990.
```
**Eval score and judgements**
```
Score: 0.5
Judgements:
- The provided context states that Tim Berners-Lee created the first ever website.
- The provided context does not mention the date of publication of the first ever website.
```
#### **Context Relevancy**
Measures the overall relevance of the information presented in supporting context/documents with regard to the prompt.
This metric can be used as a proxy for the quality of your RAG pipeline.
This evaluation recipe requires each retrieved chunk to be passed in a separate `document` turn in the input messages.
The output score is an average, computed by the ratio of chunks that contain information relevant to answering the user query / total number of input chunks
(which equals the # of document turns in the prompt).
**Input messages**
```json theme={null}
[
{"role":"system", "content":"You are a helpful bot, that responds only based on the context provided."},
{"role":"document", "content": "The first website was created and published by Tim Berners-Lee."},
{"role": "document", "content": "Tim Berners-Lee is a computer scientist that invented the world wide web."},
{"role": "user", "content": "Who published the first working website on the world wide web?"}
]
```
**Completion**
```
The first website was published by Tim Berners-Lee in August 1990.
```
**Eval score and judgements**
```
Score: 0.5
Judgements:
- The provided context states that Tim Berners-Lee created the first ever website.
- The provided context does not mention the date of publication of the first ever website.
```
#### **Context Relevancy**
Measures the overall relevance of the information presented in supporting context/documents with regard to the prompt.
This metric can be used as a proxy for the quality of your RAG pipeline.
This evaluation recipe requires each retrieved chunk to be passed in a separate `document` turn in the input messages.
The output score is an average, computed by the ratio of chunks that contain information relevant to answering the user query / total number of input chunks
(which equals the # of document turns in the prompt).
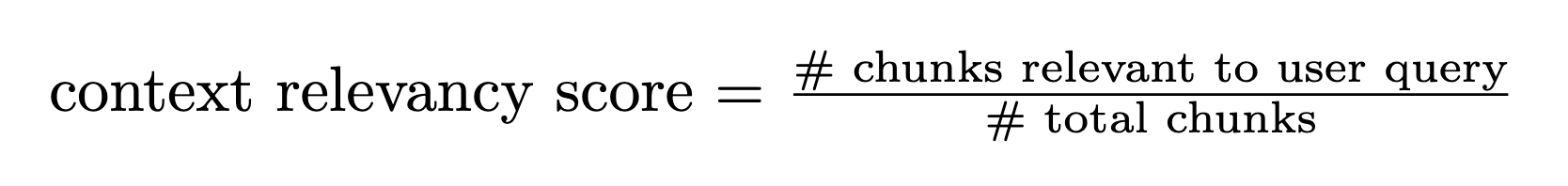 **Input messages**
```json theme={null}
[
{"role":"document", "content": "The first website was created and published by Tim Berners-Lee."},
{"role": "document", "content": "Tim Berners-Lee is a computer scientist that invented the world wide web."},
{"role": "user", "content": "Who published the first working website on the world wide web?"}
]
```
**Eval score and judgements**
```
Score: 0.5
Judgements:
- The context provides relevant information regarding the publisher of the first working website.
- The context specifies who invented the world wide web, but includes no information regarding the publisher of the first working website.
```
#### **Answer relevancy**
Measures the overall relevance/effectiveness of a completion when it comes to answering the user query.
This metric is useful to evaluate the balance of conciseness vs. extra "chattiness" of completions.
As a first step, the AI Judge breaks down the completion into individual atomic "claims".
The output score is an average, computed by the ratio of claims that directly answer the user's query / total number of claims made in the completion.
**Input messages**
```json theme={null}
[
{"role":"document", "content": "The first website was created and published by Tim Berners-Lee."},
{"role": "document", "content": "Tim Berners-Lee is a computer scientist that invented the world wide web."},
{"role": "user", "content": "Who published the first working website on the world wide web?"}
]
```
**Eval score and judgements**
```
Score: 0.5
Judgements:
- The context provides relevant information regarding the publisher of the first working website.
- The context specifies who invented the world wide web, but includes no information regarding the publisher of the first working website.
```
#### **Answer relevancy**
Measures the overall relevance/effectiveness of a completion when it comes to answering the user query.
This metric is useful to evaluate the balance of conciseness vs. extra "chattiness" of completions.
As a first step, the AI Judge breaks down the completion into individual atomic "claims".
The output score is an average, computed by the ratio of claims that directly answer the user's query / total number of claims made in the completion.
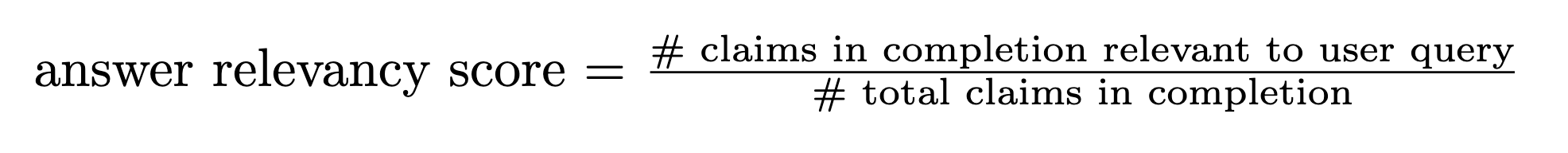 **Input messages**
```json theme={null}
[
{"role":"system", "content":"You are a helpful bot, that responds only based on the context provided."},
{"role":"document", "content": "The first website was created and published by Tim Berners-Lee."},
{"role": "document", "content": "Tim Berners-Lee is a computer scientist that invented the world wide web."},
{"role": "user", "content": "Who published the first working website on the world wide web?"}
]
```
**Completion**
```
The first website was published by Tim Berners-Lee in August 1990. Tim Berners-Lee himself was the inventor of the world wide web.
```
**Eval score and judgements**
```
Score: 0.5
Judgements:
- The first claim is directly relevant to the user's query.
- Although it is related, the user's query does not seek information about the inventor of the world wide web.
```
## Custom evaluation recipes
#### **Custom guidelines evaluation**
Define your own evaluation guidelines.
Guidelines are sets of individual evaluation criteria expressed in natural language, that aim to verify adherence to a specific behaviour.
Guidelines should be phrased in a similar fashion to: "The completion must ... *replace desired behaviour*"\*
(refer to [*Tips on writing effective evaluation guidelines*](#tips-on-writing-effective-evaluation-guidelines) below for examples).
Completions will be evaluated against each individual guideline,
and judged as compliant (`score = 1`) or not compliant (`score = 0`) with the guideline.
The output score is the average computed across all scores for individual guidelines.
The textual judgement attached to each completion contains one reasoning trace per guideline, indicating why the completion did or did not adhere to the guideline.
**Input messages**
```json theme={null}
[
{"role":"system", "content":"You are a customer support bot. Always maintain a professional tone, don't use gender-specific pronouns, and always start with a polite greeting."},
{"role": "user", "content": "I need a refund now!"}
]
```
**Completion**
```
Sorry to hear you had problems with our product. Could you share your order ID?
```
**Evaluation Guidelines**
```json theme={null}
[
{
"name": "tone",
"description": "The completion must maintain a professional tone throughout, no matter the circumstance."
},
{
"name": "gender-pronoun-avoidance",
"description": "No gender-pronouns should be used to address the user."
},
{
"name": "polite-greeting",
"description": "The completion should always start with a polite greeting such as 'Thank you for contacting us` or something equally polite."
}
]
```
**Eval score and judgements**
```
Score: 0.67
Judgements:
- The completions maintains a profession tone.
- No gender-specific pronouns are used.
- The completion does not start with a polite greeting.
```
For best custom evaluation performance, it is recommended that each input guideline is atomic - i.e. evaluates a single behaviour -, and there is minimal overlap
in what is being evaluated across guidelines. This will guarantee that each desired behaviour is evaluated only once, and that the score for each behaviour is not affected
by small failures on additional directives bundled into the same guideline.
✅ Example of good guidelines (atomic):
```json theme={null}
[
{
"name": "tone",
"description": "The completion must maintain a professional tone throughout, no matter the circumstance."
},
{
"name": "gender-pronoun-avoidance",
"description": "No gender-pronouns should be used to address the user."
},
{
"name": "polite-greeting",
"description": "The completion should always start with a polite greeting such as 'Thank you for contacting us` or something equally polite."
}
]
```
❌ Example of bad guidelines (too broad/bundled):
```json theme={null}
[
{
"name": "tone-gender-polite-greeting",
"description": "The completion must be maintain a professional tone throughout, no matter the circumstance. Also, no gender-specific pronouns should be used, and the response should always start with a polite greeting such as 'Thank you for contacting us' or something equally polite."
}
]
```
See the [SDK Reference](https://adaptive-ml.github.io/adaptive-sdk-docs/adaptive_sdk/resources.html#EvalJobs.create) for the full specification
on evaluation job creation.
**Input messages**
```json theme={null}
[
{"role":"system", "content":"You are a helpful bot, that responds only based on the context provided."},
{"role":"document", "content": "The first website was created and published by Tim Berners-Lee."},
{"role": "document", "content": "Tim Berners-Lee is a computer scientist that invented the world wide web."},
{"role": "user", "content": "Who published the first working website on the world wide web?"}
]
```
**Completion**
```
The first website was published by Tim Berners-Lee in August 1990. Tim Berners-Lee himself was the inventor of the world wide web.
```
**Eval score and judgements**
```
Score: 0.5
Judgements:
- The first claim is directly relevant to the user's query.
- Although it is related, the user's query does not seek information about the inventor of the world wide web.
```
## Custom evaluation recipes
#### **Custom guidelines evaluation**
Define your own evaluation guidelines.
Guidelines are sets of individual evaluation criteria expressed in natural language, that aim to verify adherence to a specific behaviour.
Guidelines should be phrased in a similar fashion to: "The completion must ... *replace desired behaviour*"\*
(refer to [*Tips on writing effective evaluation guidelines*](#tips-on-writing-effective-evaluation-guidelines) below for examples).
Completions will be evaluated against each individual guideline,
and judged as compliant (`score = 1`) or not compliant (`score = 0`) with the guideline.
The output score is the average computed across all scores for individual guidelines.
The textual judgement attached to each completion contains one reasoning trace per guideline, indicating why the completion did or did not adhere to the guideline.
**Input messages**
```json theme={null}
[
{"role":"system", "content":"You are a customer support bot. Always maintain a professional tone, don't use gender-specific pronouns, and always start with a polite greeting."},
{"role": "user", "content": "I need a refund now!"}
]
```
**Completion**
```
Sorry to hear you had problems with our product. Could you share your order ID?
```
**Evaluation Guidelines**
```json theme={null}
[
{
"name": "tone",
"description": "The completion must maintain a professional tone throughout, no matter the circumstance."
},
{
"name": "gender-pronoun-avoidance",
"description": "No gender-pronouns should be used to address the user."
},
{
"name": "polite-greeting",
"description": "The completion should always start with a polite greeting such as 'Thank you for contacting us` or something equally polite."
}
]
```
**Eval score and judgements**
```
Score: 0.67
Judgements:
- The completions maintains a profession tone.
- No gender-specific pronouns are used.
- The completion does not start with a polite greeting.
```
For best custom evaluation performance, it is recommended that each input guideline is atomic - i.e. evaluates a single behaviour -, and there is minimal overlap
in what is being evaluated across guidelines. This will guarantee that each desired behaviour is evaluated only once, and that the score for each behaviour is not affected
by small failures on additional directives bundled into the same guideline.
✅ Example of good guidelines (atomic):
```json theme={null}
[
{
"name": "tone",
"description": "The completion must maintain a professional tone throughout, no matter the circumstance."
},
{
"name": "gender-pronoun-avoidance",
"description": "No gender-pronouns should be used to address the user."
},
{
"name": "polite-greeting",
"description": "The completion should always start with a polite greeting such as 'Thank you for contacting us` or something equally polite."
}
]
```
❌ Example of bad guidelines (too broad/bundled):
```json theme={null}
[
{
"name": "tone-gender-polite-greeting",
"description": "The completion must be maintain a professional tone throughout, no matter the circumstance. Also, no gender-specific pronouns should be used, and the response should always start with a polite greeting such as 'Thank you for contacting us' or something equally polite."
}
]
```
See the [SDK Reference](https://adaptive-ml.github.io/adaptive-sdk-docs/adaptive_sdk/resources.html#EvalJobs.create) for the full specification
on evaluation job creation.