> ## Documentation Index
> Fetch the complete documentation index at: https://docs.adaptive-ml.com/llms.txt
> Use this file to discover all available pages before exploring further.
# Create an evaluation recipe
> Write your own recipe for model evaluation, and log eval artifacts to the product
Writing an evaluation recipe requires three main components:
2. **A dataset** - Data to evaluate the models on
3. **Models to evaluate** - The models you want to assess
4. **Graders** - Functions that will score the model outputs
An Evaluation recipe should produce an `EvaluationArtifact`, which will be populated with several `EvalSample` (evaluated model's completions with attached grades). When you visit the Adaptive UI, and `EvaluationArtifact` will show aggregate evaluation scores per model on all Graders selected/created in the evaluation.
## Evaluation recipe structure
In the previous sections, we omit wrapping all methods in the main function decorated with @recipe\_main (see context [here](/v0.12/harmony/recipe-syntax)) for readability. Assume all the following code is in the main function. Also, check [Parametrize recipe inputs](/v0.12/harmony/config) to learn how to build the recipe `config` with datasets, models and graders we refer to in the next steps.
### 1. Load a dataset
```python theme={null}
# Load from Adaptive
dataset = await config.dataset.load(ctx)
```
### 2. Spawn models and generate completions
To evaluate your models, you'll generate a list of `EvalSampleInteraction` by spawning each model, running inference to obtain completions, and collecting the results.
Use the `spawn_inference` method to create an inference instance for each model. After generating completions, deallocate the model to optimize memory usage.
```python theme={null}
from adaptive_harmony import EvalSampleInteraction, Grade
from adaptive_harmony.core.utils import batch_process_fallible
# Register stages for progress tracking
models_list = list(config.models_to_evaluate)
stage_names = [f"generate_model_{i}" for i in range(len(models_list))]
ctx.job.register_stages(stage_names)
interactions: list[EvalSampleInteraction] = []
# models_to_evaluate is a Set[Model]
for i, model_param in enumerate(models_list):
model_builder = await model_param.to_builder(ctx)
model = await model_builder.spawn_inference(model_param.model_key)
# Generate completions with progress reporting
result_pairs = await batch_process_fallible(
model.generate,
dataset,
batch_size=100,
stage_notifier=ctx.job.stage_notifier(stage_names[i])
)
completions = [result for idx, result in result_pairs]
interactions.extend(
[
EvalSampleInteraction(
thread=thread,
source=model_param.model_key,
)
for thread in completions
]
)
# remove the model from GPU
await model.dealloc()
```
The [`batch_process_fallible`](/v0.12/harmony/async-utils) utility function concurrently processes all samples with automatic progress reporting and skips completions with errors (when for example the sample is too big for the model's maximum sequence length).
### 3. Spawn graders and grade completions
To evaluate model outputs, we need to create/setup graders, and use them to grade each model's completions.
Each Grader produces a [Grade](/v0.12/harmony/graders#grade-object) for each sample.
```python theme={null}
from adaptive_harmony import EvalSample
# Create graders from config
graders = [await grader.load(ctx) for grader in config.graders]
# Define eval samples with empty grades
eval_samples = [
EvalSample(
interaction=interaction,
grades=[],
dataset_key=config.dataset.dataset_key,
) for interaction in interactions
]
# Register grading stages for progress tracking
grading_stage_names = [f"grade_{i}" for i in range(len(graders))]
ctx.job.register_stages(grading_stage_names)
# Grade eval samples with progress reporting
for i, grader in enumerate(graders):
threads = [sample.interaction.thread for sample in eval_samples]
grade_pairs = await batch_process_fallible(
grader.grade,
threads,
batch_size=100,
stage_notifier=ctx.job.stage_notifier(grading_stage_names[i])
)
# Create index-to-grade mapping for successful grades
grade_map = {idx: grade for idx, grade in grade_pairs}
# Attach grades to eval samples (skip failed ones)
for i, eval_sample in enumerate(eval_samples):
if i in grade_map:
eval_sample.grades.append(grade_map[i])
```
If you defined a [custom Recipe Grader](/v0.12/harmony/graders) in this eval recipe, you could add it to the `graders` list above, have its grades added to `eval_samples` and later shown in the UI. If the `grader_key` you hardcode for you recipe grader does not exist yet in the platform, it will be automatically created and reported in the evaluation results; no need to pre-create the recipe grader.
### 4. Output an EvaluationArtifact
Now that all samples are graded, you can create an `EvaluationArtifact` and populate it with your `EvalSamples`.
You do not need to push this to Adaptive with a specific method; the Adaptive Engine automatically detects that an `EvaluationArtifact` was written in the course of the recipe's execution, registering and displaying it in the UI once the run is complete.
Read more about Artifacts in [Run output artifacts](/v0.12/harmony/artifacts).
```python theme={null}
# Create evaluation artifact
eval_artifact = EvaluationArtifact(name="Evaluation Artifact", ctx=ctx)
eval_artifact.add_samples(eval_samples)
```
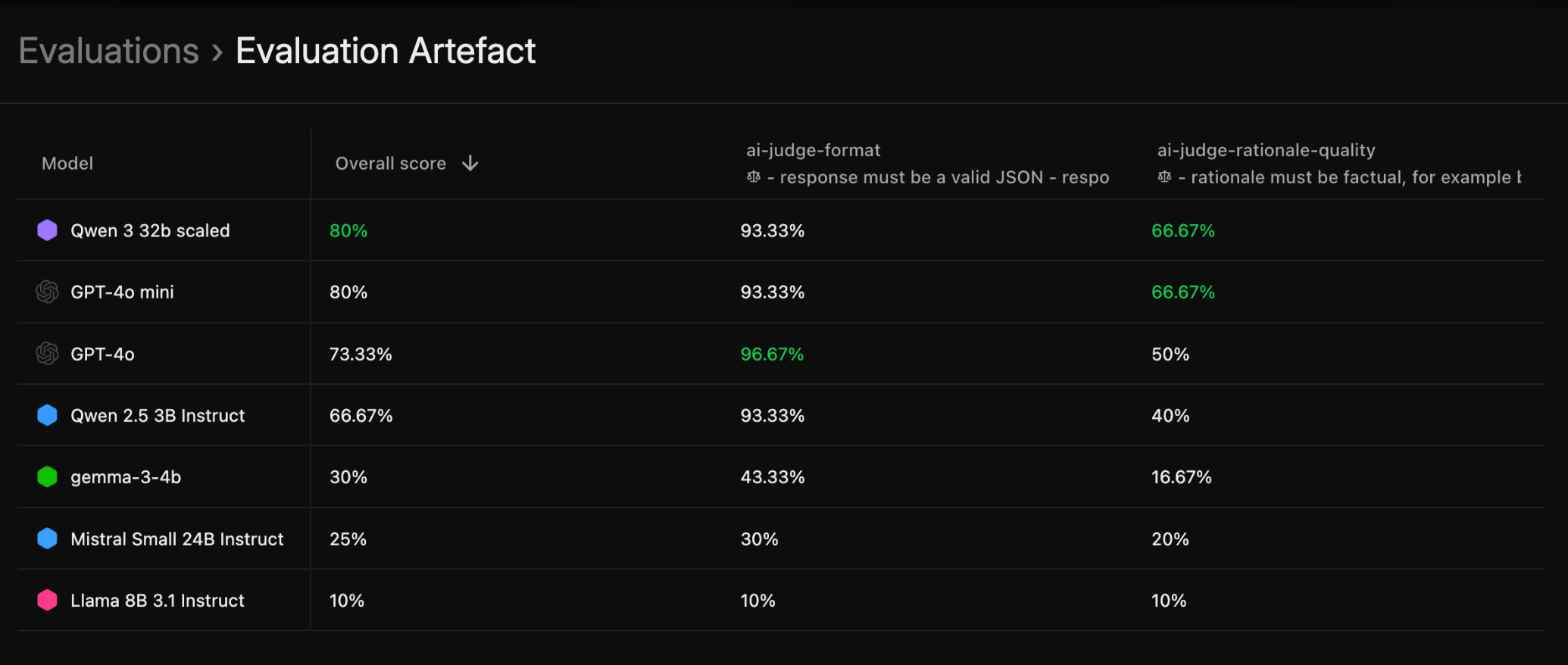
Evaluation table, result of saving an EvaluationArtifact}>
 ## Complete example
Here's a complete example combining all the concepts:
```python theme={null}
from pydantic import Field
from typing import Annotated
from loguru import logger
from adaptive_harmony import StringThread, EvalSample, EvalSampleInteraction, EvaluationArtifact
from adaptive_harmony.runtime import InputConfig, RecipeContext, recipe_main
from adaptive_harmony.parameters import Model, Dataset, Grader
from adaptive_harmony.core.utils import batch_process_fallible
class EvalConfig(InputConfig):
dataset: Annotated[Dataset, Field(description="Dataset to evaluate on")]
model_1: Annotated[Model, Field(description="First model to evaluate")]
model_2: Annotated[Model, Field(description="Second model to evaluate")]
tp_1: Annotated[int, Field(description="Tensor parallel degree for model 1", default=1)]
tp_2: Annotated[int, Field(description="Tensor parallel degree for model 2", default=1)]
graders: Annotated[
list[Grader],
Field(description="List of graders to evaluate models with"),
]
@recipe_main
async def complete_evaluation_recipe(config: EvalConfig, ctx: RecipeContext):
client = ctx.client
# 1. Load dataset
logger.info("Loading dataset...")
dataset = await config.dataset.load(ctx)
logger.info(f"Loaded {len(dataset)} samples")
# 2. Spawn models and run completions
logger.info("Running inference for both models...")
# Register stages for progress tracking
ctx.job.register_stages(["generate_model_1", "generate_model_2"])
model_1_builder = await config.model_1.to_builder(ctx, tp=config.tp_1)
model_1 = await model_1_builder.spawn_inference("evaluated_model_1")
model_2_builder = await config.model_2.to_builder(ctx, tp=config.tp_2)
model_2 = await model_2_builder.spawn_inference("evaluated_model_2")
# Generate completions with progress reporting
stage_notifier_1 = ctx.job.stage_notifier("generate_model_1")
result_pairs_1 = await batch_process_fallible(
model_1.generate,
dataset,
batch_size=100,
stage_notifier=stage_notifier_1
)
completions_1 = [result for idx, result in result_pairs_1]
stage_notifier_2 = ctx.job.stage_notifier("generate_model_2")
result_pairs_2 = await batch_process_fallible(
model_2.generate,
dataset,
batch_size=100,
stage_notifier=stage_notifier_2
)
completions_2 = [result for idx, result in result_pairs_2]
logger.info(f"Generated {len(completions_1)} completions for model 1")
logger.info(f"Generated {len(completions_2)} completions for model 2")
# Deallocate models to free GPU resources
await model_1.dealloc()
await model_2.dealloc()
# 3. Spawn graders and grade completions
logger.info("Setting up graders...")
graders = [await grader.load(ctx) for grader in config.graders]
# Create interactions for both models
interactions = []
for completion in completions_1:
interactions.append(EvalSampleInteraction(thread=completion, source="model_1"))
for completion in completions_2:
interactions.append(EvalSampleInteraction(thread=completion, source="model_2"))
# Create eval samples
eval_samples = [
EvalSample(
interaction=interaction,
grades=[],
dataset_key=config.dataset.dataset_key,
) for interaction in interactions
]
# Register grading stages for progress tracking
grading_stage_names = [f"grade_{i}" for i in range(len(graders))]
ctx.job.register_stages(grading_stage_names)
# Grade all samples with progress reporting
for i, grader in enumerate(graders):
logger.info(f"Running {grader.grader_key} grader...")
stage_notifier = ctx.job.stage_notifier(grading_stage_names[i])
threads = [sample.interaction.thread for sample in eval_samples]
grade_pairs = await batch_process_fallible(
grader.grade,
threads,
batch_size=100,
stage_notifier=stage_notifier
)
# Create index-to-grade mapping for successful grades
grade_map = {idx: grade for idx, grade in grade_pairs}
# Attach grades to eval samples (skip failed ones)
for i, eval_sample in enumerate(eval_samples):
if i in grade_map:
eval_sample.grades.append(grade_map[i])
# 4. Create evaluation artifact
eval_artifact = EvaluationArtifact(name="Evaluation Artifact", ctx=ctx)
eval_artifact.add_samples(eval_samples)
logger.info(f"Evaluation completed! Created {len(eval_samples)} eval samples")
```
## Key components explained
### Evaluation Samples
Each evaluation sample contains:
* **Interaction**: The model's response and source model key
* **Grades**: Grades from all graders
* **Dataset ID**: Reference to the source dataset
### Graders
Graders can be:
* **AI Judge Graders**: Use LLMs to score responses
* **Rule-based Graders**: Apply predefined criteria
* **Combined Graders**: Aggregate multiple grader scores
### Evaluation Artifact
The `EvaluationArtifact` class:
* Collects all evaluation results
* Provides methods to analyze and export results
* Integrates with the Adaptive platform for result tracking
## Best Practices
1. **Model Management**: Always deallocate models after use to free resources
2. **Error Handling**: Use proper error handling for robust evaluation
3. **Progress Tracking**: Provide clear logging for debugging and monitoring
4. **Resource Cleanup**: Properly clean up graders and models
## Complete example
Here's a complete example combining all the concepts:
```python theme={null}
from pydantic import Field
from typing import Annotated
from loguru import logger
from adaptive_harmony import StringThread, EvalSample, EvalSampleInteraction, EvaluationArtifact
from adaptive_harmony.runtime import InputConfig, RecipeContext, recipe_main
from adaptive_harmony.parameters import Model, Dataset, Grader
from adaptive_harmony.core.utils import batch_process_fallible
class EvalConfig(InputConfig):
dataset: Annotated[Dataset, Field(description="Dataset to evaluate on")]
model_1: Annotated[Model, Field(description="First model to evaluate")]
model_2: Annotated[Model, Field(description="Second model to evaluate")]
tp_1: Annotated[int, Field(description="Tensor parallel degree for model 1", default=1)]
tp_2: Annotated[int, Field(description="Tensor parallel degree for model 2", default=1)]
graders: Annotated[
list[Grader],
Field(description="List of graders to evaluate models with"),
]
@recipe_main
async def complete_evaluation_recipe(config: EvalConfig, ctx: RecipeContext):
client = ctx.client
# 1. Load dataset
logger.info("Loading dataset...")
dataset = await config.dataset.load(ctx)
logger.info(f"Loaded {len(dataset)} samples")
# 2. Spawn models and run completions
logger.info("Running inference for both models...")
# Register stages for progress tracking
ctx.job.register_stages(["generate_model_1", "generate_model_2"])
model_1_builder = await config.model_1.to_builder(ctx, tp=config.tp_1)
model_1 = await model_1_builder.spawn_inference("evaluated_model_1")
model_2_builder = await config.model_2.to_builder(ctx, tp=config.tp_2)
model_2 = await model_2_builder.spawn_inference("evaluated_model_2")
# Generate completions with progress reporting
stage_notifier_1 = ctx.job.stage_notifier("generate_model_1")
result_pairs_1 = await batch_process_fallible(
model_1.generate,
dataset,
batch_size=100,
stage_notifier=stage_notifier_1
)
completions_1 = [result for idx, result in result_pairs_1]
stage_notifier_2 = ctx.job.stage_notifier("generate_model_2")
result_pairs_2 = await batch_process_fallible(
model_2.generate,
dataset,
batch_size=100,
stage_notifier=stage_notifier_2
)
completions_2 = [result for idx, result in result_pairs_2]
logger.info(f"Generated {len(completions_1)} completions for model 1")
logger.info(f"Generated {len(completions_2)} completions for model 2")
# Deallocate models to free GPU resources
await model_1.dealloc()
await model_2.dealloc()
# 3. Spawn graders and grade completions
logger.info("Setting up graders...")
graders = [await grader.load(ctx) for grader in config.graders]
# Create interactions for both models
interactions = []
for completion in completions_1:
interactions.append(EvalSampleInteraction(thread=completion, source="model_1"))
for completion in completions_2:
interactions.append(EvalSampleInteraction(thread=completion, source="model_2"))
# Create eval samples
eval_samples = [
EvalSample(
interaction=interaction,
grades=[],
dataset_key=config.dataset.dataset_key,
) for interaction in interactions
]
# Register grading stages for progress tracking
grading_stage_names = [f"grade_{i}" for i in range(len(graders))]
ctx.job.register_stages(grading_stage_names)
# Grade all samples with progress reporting
for i, grader in enumerate(graders):
logger.info(f"Running {grader.grader_key} grader...")
stage_notifier = ctx.job.stage_notifier(grading_stage_names[i])
threads = [sample.interaction.thread for sample in eval_samples]
grade_pairs = await batch_process_fallible(
grader.grade,
threads,
batch_size=100,
stage_notifier=stage_notifier
)
# Create index-to-grade mapping for successful grades
grade_map = {idx: grade for idx, grade in grade_pairs}
# Attach grades to eval samples (skip failed ones)
for i, eval_sample in enumerate(eval_samples):
if i in grade_map:
eval_sample.grades.append(grade_map[i])
# 4. Create evaluation artifact
eval_artifact = EvaluationArtifact(name="Evaluation Artifact", ctx=ctx)
eval_artifact.add_samples(eval_samples)
logger.info(f"Evaluation completed! Created {len(eval_samples)} eval samples")
```
## Key components explained
### Evaluation Samples
Each evaluation sample contains:
* **Interaction**: The model's response and source model key
* **Grades**: Grades from all graders
* **Dataset ID**: Reference to the source dataset
### Graders
Graders can be:
* **AI Judge Graders**: Use LLMs to score responses
* **Rule-based Graders**: Apply predefined criteria
* **Combined Graders**: Aggregate multiple grader scores
### Evaluation Artifact
The `EvaluationArtifact` class:
* Collects all evaluation results
* Provides methods to analyze and export results
* Integrates with the Adaptive platform for result tracking
## Best Practices
1. **Model Management**: Always deallocate models after use to free resources
2. **Error Handling**: Use proper error handling for robust evaluation
3. **Progress Tracking**: Provide clear logging for debugging and monitoring
4. **Resource Cleanup**: Properly clean up graders and models